Szövegegyezések vizsgálata tudományos szövegekben
A Crossref Similarity Check felületén keresztül használható az iThenticate – az tudományos szövegek eredetiségének ellenőrzését segítő szövegegyezőség vizsgáló – szolgáltatás.
Az iThenticate összehasonlítja a kéziratot saját folyamatosan bővülő adatbázisával, amely nagyszámú (több tízmillió) dokumentumot tartalmaz tudományos konferenciákról, folyóiratokból és könyvekből. Az eszköz keresést végez az interneten és több más tartalomszolgáltató adatbázisában is.
Fetöltés
A szolgáltatás jelenleg könyvtárosi feltöltéssel vehető igénybe. A vizsgálat a szolg@uni-corvinus.hu címre küldött e-mailben kérhető.
A kötelező adatok (keresztnév, vezetéknév, dokumentum címe) mellett a vizsgálandó dokumentumra az alábbi követelmények érvényesek:
- kisebb méretű, mint 100MB;
- legfeljebb 800 oldal;
- legalább 20 szavas szövegnek kell lennie;
- a csak szöveges fájlok nem haladhatják meg a 2MB-ot;
- a tömörített fájlok maximális mérete 200MB vagy 1000 fájl.
Jelenleg az alábbi fájlok feltöltése lehetséges:
MS Word (doc, docx), Text (txt), PostScript, PDF, HTML, Excel, PowerPoint, Word Perfect WPD, OpenOffice ODT, RTF, Hangul HWP
Amint elkészül a dokumentum ellenőrzése, a program létrehoz egy hasonlósági indexet (similarity index), a százalékos eredményre kattintva megtekinthetőek a részletek. Általában a hasonlósági pontszámot használják annak mérésére, hogy mennyire hasonlít egy kézirat a korábban közzétett szöveghez.
Az iThenticate rendszerben hasonlósági indexre kattintás után ez az ablak jelenik meg:
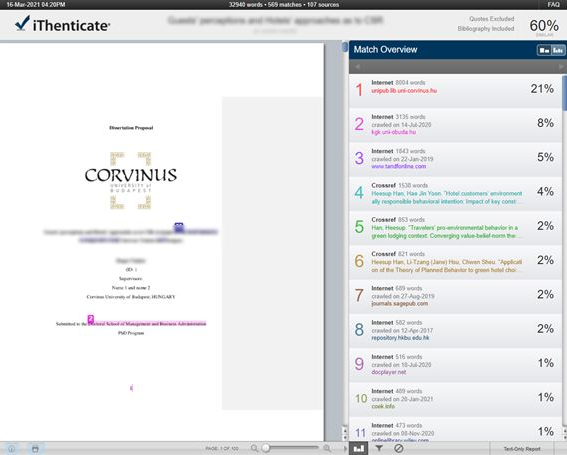
A teljes kézirat általános hasonlósági indexe a jobb felső sarokban található. Az Egyezés áttekintése (match overview) megmutatja a felhasználónak, hogy mely adatbázis-forrásokat kell megvizsgálnia az esetleges szövegegyezőség miatt, és megmutatja az adott források hasonlósági indexét és a hasonló szavak számát.
A hasonlósági index mellett látható néhány, a felhasználó által kiválasztott kizárás (pl. idézett szöveg vagy a bibliográfia szűrve van-e).
A jelentés a fő szövegben (bal oldalon) szám és szín szerint is kiemeli a konkrét forrásokat, hogy a felhasználó gyorsan lássa, mely szövegterületek lehetnek problémásak.
Mit tartalmaz az iThenticate similarity report?
- A kéziratot kiemelt részekkel. A kiemelt részek a már publikált anyagokkal összevetett hasonlóságot jelzik.
- A konkrét források felsorolását. Ezeket a forrásokat százalékos arányban rangsorolják attól függően mekkora a hasonlóság a kézirat szövegéhez.
- Hasonlósági indexet. A hasonlósági index a kézirat és a közzétett szöveg teljes százalékos hasonlósága. A hamis pozitív adatok kockázatának csökkentése érdekében érdemes csak a kézirat fő szövegére alkalmazni, az irodalomjegyzékre és az idézetekre nem.
Ezenkívül kizárhatók a közzétett forrásokhoz hasonló módon megjelölt rövid szövegrészek (< 10 szó).
Az oldalról letölthető a PDF jelentés, amelyben az egyezés áttekintése általában a kiemelt cikk végén található. Kevesebb a dinamikus funkcionalitás a PDF-fájlban, de a PDF végén található néhány adatbázis-forrás kattintással elérhető, így eljuthatunk a megfelelő anyaghoz. Alternatív megoldásként a fő szöveg színkódolásával meg lehet nézni, hogy mely mondatok felelnek meg a számozott forrásoknak.
Milyen szintű hasonlóság megengedett?
Nincs általánosan elfogadott hasonlósági százalékhatár. Néha a magasabb hasonlósági pontszám kevésbé problematikus, mint például egy alacsonyabb hasonlósági pontszámú cikk, de olyan bekezdést tartalmaz, amelyet közvetlenül másoltak át egy másik forrásból.
Hogyan kell használni az iThenticate similarity report-ot?
Különös figyelmet kell fordítani ezekre a kérdésekre:
- Nagy hasonlóságú szövegtömbök, például egy egész mondat vagy egy mondatsor ugyanazon bekezdésen belül
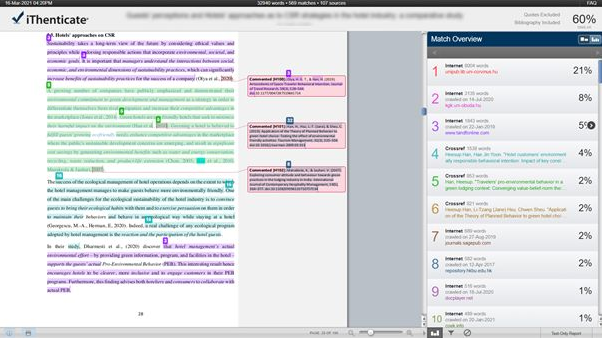
- Ismételt hasonlóság ugyanazon forrással (forrásokkal)
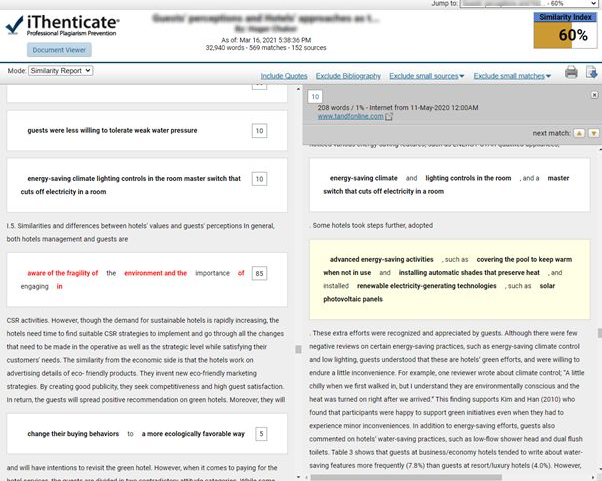
A következő kérdések kevésbé aggasztóak:
- Hasonló szöveg, amely a szakterületén általánosan használt szabványos kifejezésekből áll, ahelyett, hogy egy vagy néhány konkrét forrásra vonatkozna;
- Hasonló szöveg, amely a korábban publikált módszerek leírásából áll.